Link to KY documentation – https://dok.kombit.dk/arbejdsmarked-og-beskaeftigelse/kommunernes-ydelessystem-ky
1. Pagination / Extracting data from tables #
Some problems start when extracting data from the pages. You don’t get all the results at once, and you have to click through several pages to see all the data. If you use an Extract data from web page with a pager to click next and extract data, it will continue indefinitely. The problem is that the Next button in the example below does not change when it is clicked, and is available all the time. Then if you use Recorder to try to extract everything, the robot will always click Next , because nothing in the Selector or CSS part changes, so it knows to stop.
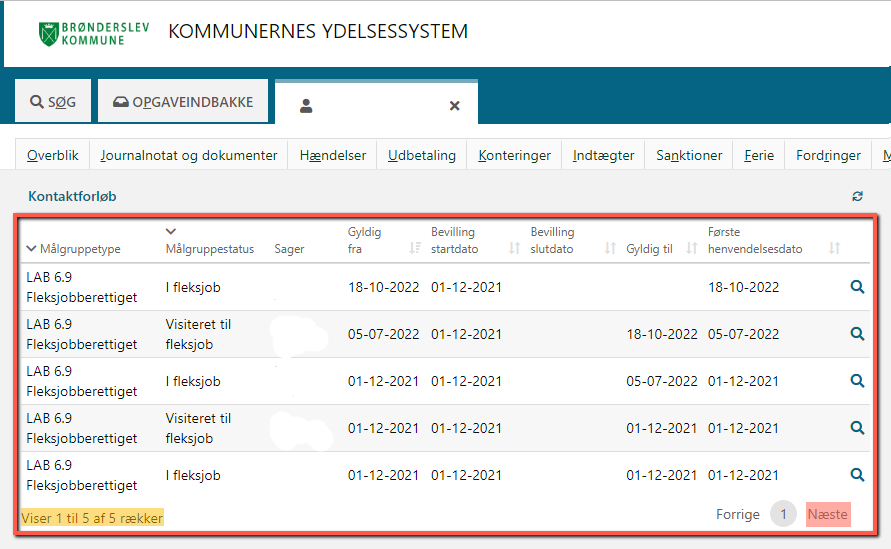
There are two solutions that can be used according to different needs, which will be discussed below. Solution 1 is to extract everything indiscriminately, if you need this. Solution 2 extracts data per page individually, until you have found what you are looking for. This requires that you store the data somewhere, if it is not to be exceeded from page to page. In cases with dates and separators, this can be faster than the first one.
1.1 Solution 1 – Calculate the last page and extract all data #
A solution to get around this is to extract the text from the div that contains the page number, and then run a regex match on it to find out how many pages there are. The text itself that comes out of Get details can look in two ways. In the code, we first check with regex \d+ , which combines the number into a chain if there is nothing separating them. If there are many pages, we will get two numbers, in the example below 12345 and 55 in a list. If this is the case, we would like to extract the 55 pages. If there are no pages to be divided in this way, we know that the page number is small, and therefore only one digit. To do this, we match with \d{1} which separates each number with a digit. In this we are interested in the last number in the list, and therefore need to use the amount of items in this -1, since the index in lists starts at 0. We therefore know that the last number in the list must be the last page, and can then extract this.
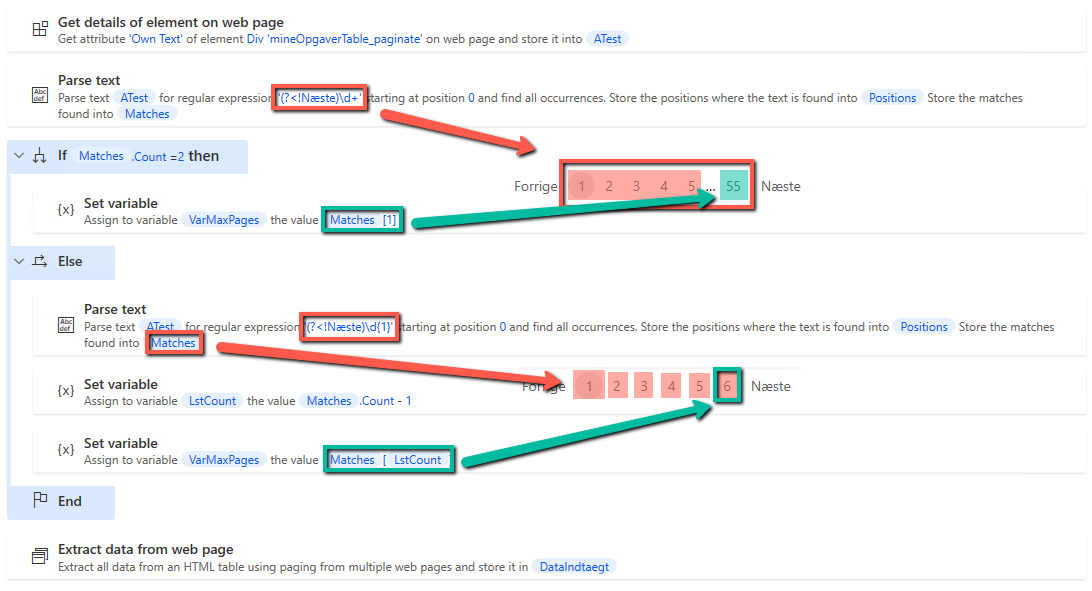
In the extract itself, you will turn on Only the first , and then enter the variable for the maximum number of pages. The robot will then print up to and including the last page and extract the data.
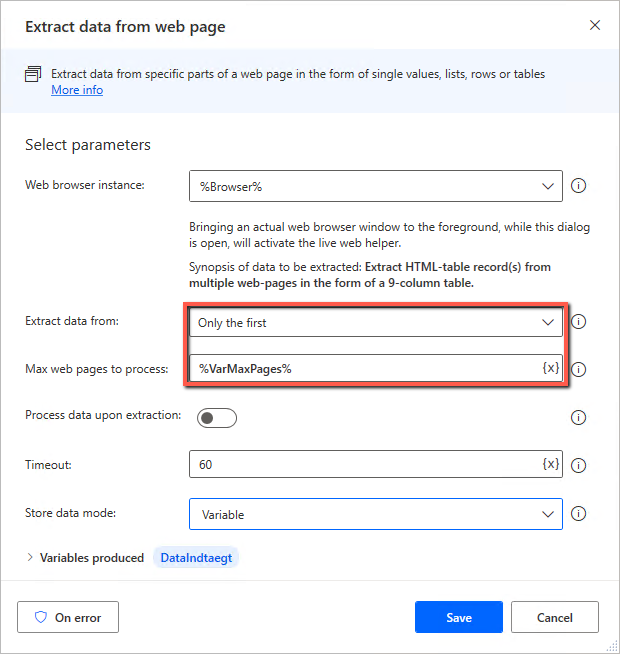
1.2 Solution 2 – Extract data per page until you find what you are looking for #
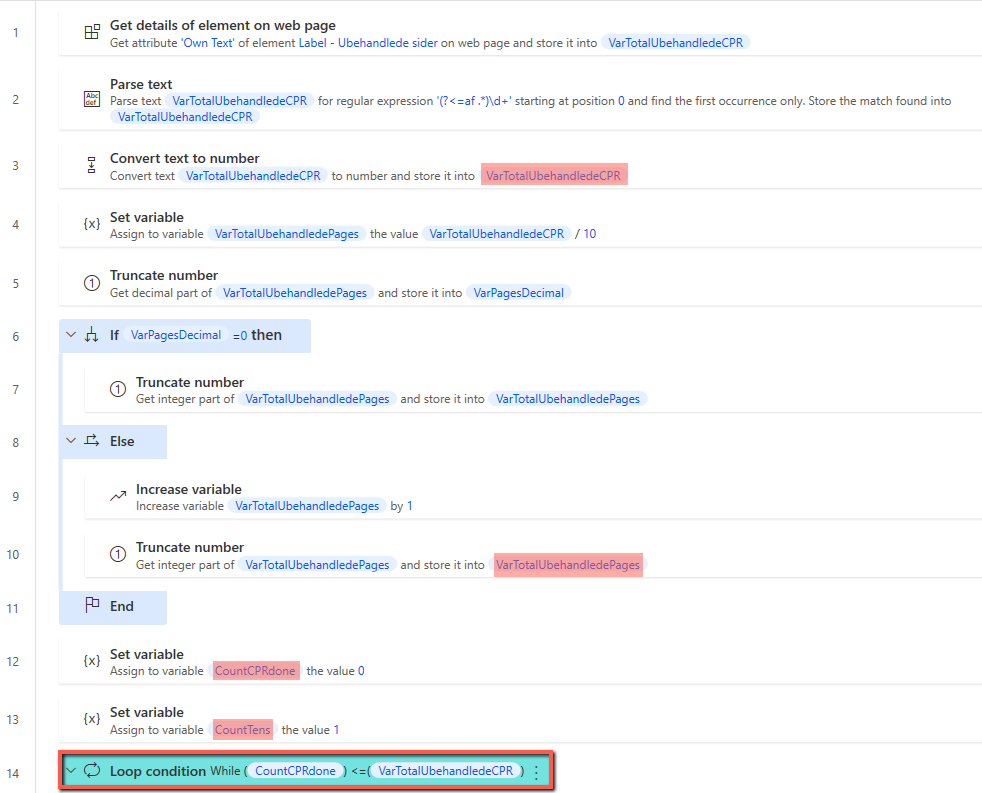
Another way around this is to create a loop condition that automatically stops the robot. It should be mentioned that data will be exceeded at each iteration of the loop, so you need to build a method into this to save data if you need it ( for example, a foreach built from the Output that comes, put data into an excel sheet or similar, next loop append to this, etc. ).
To start with, we can subtract the total number of rows, marked in yellow in the image, and then calculate how many pages there are in total. We divide by 5, as this is the number of rows per page. Furthermore, we must have extracted the correct integer, for this purpose we look at the decimal. If the decimal is .00, it is assumed that it is a whole 5, and we can extract it as it is. If there is something in the decimal, we must round up, as it may be 0.2 for example, this is not rounded up with a truncate , and we increment the variable manually and extract the integer afterwards.
We can then set up our loop condition , which pulls data from each page. As mentioned earlier, it overruns OutputData every time it creates a new one. If you need to use the data later, you can, as in the example below, create a for each after the extract , enter the data you need into, for example, an Excel sheet, and then pull this data out after the loop condition ends, so you can use it further in the run.
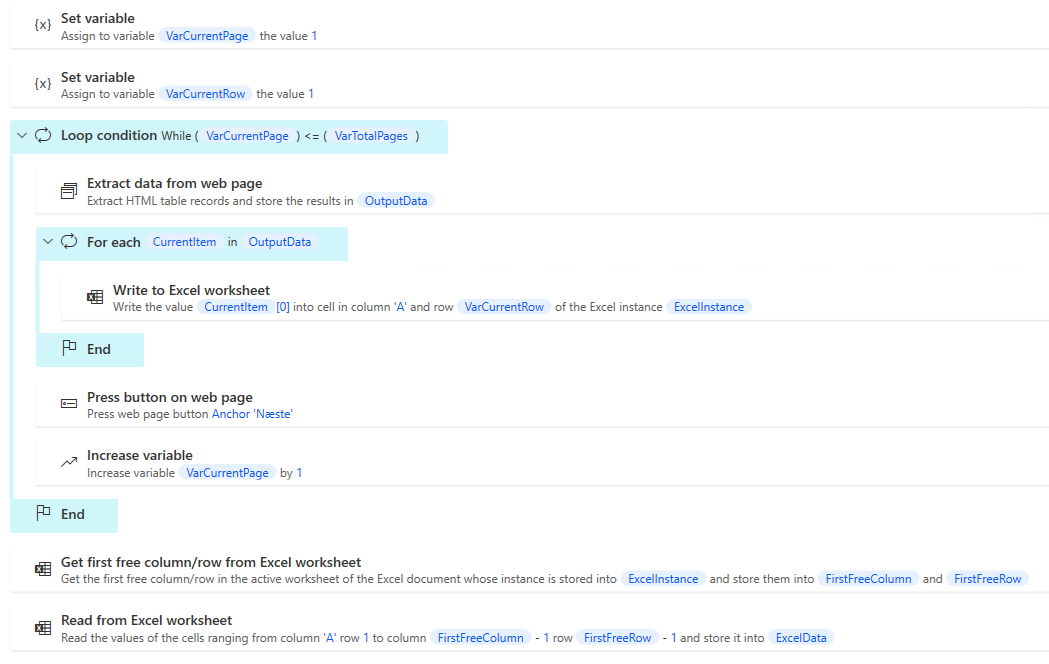
2. Loop setup #
One of the big problems with KY is the way the tables are built. Instead of a standard 0 UID from the top and then +1 ( in the example below it would be 0-9 normally ), the selector switches between Odd and Even , and counts individually on these as well. It gets even more complicated in the main menu, which we work from. In addition to keeping track of the unique selector in each row, a row disappears if the task is performed. That is, if the citizen is to be manually reviewed, the robot simply jumps to the next row. If the citizen is performed by the robot, the row disappears, and the table is pushed up in that sense. So the robot will have to click on the same row again, which is then a new citizen.
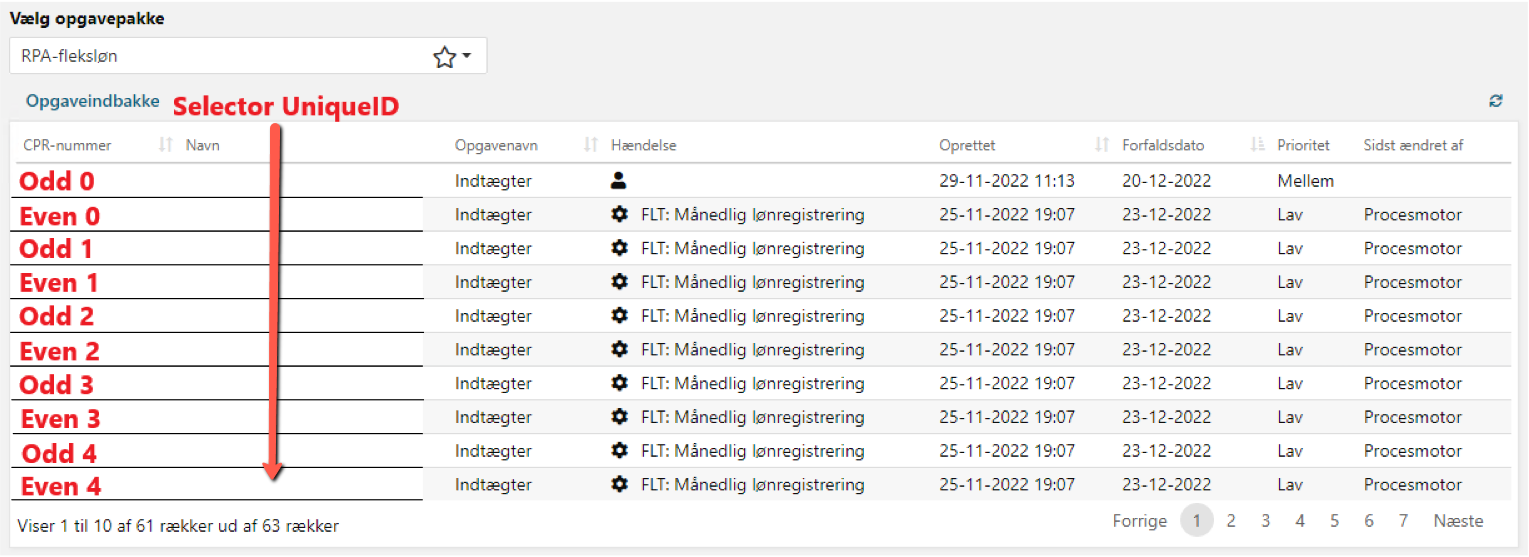
From this, there is a lot of logic to keep the robot running. If we start with the example below on a loop, we use CountCPRdone against VarTotalUnhandledCPR to keep track of when we are done, as it is the easiest condition to set, as we can +1 on CountCPRdone every time we have run a citizen in the loop. If no caseworker is working at the same time as the robot, then it should work. If they are working at the same time, they can remove from the list, which will subtract from VarTotalUnhandledCPR , which it does not check continuously. It will therefore automatically fail when it has to press its custom selector, for which it expects there is still data. VarTotalPages is used to navigate to the next page every time CountTens hits 11.
In the example , it is used to calculate the selector for the citizen table on the front page, and for the income table. BoolCPRIndt determines this at the beginning, 0 for citizen, and 1 for income. Furthermore, it is determined whether it is odd or even via BoolOddEven CPR or Indt, which then keeps track of everything. In addition, it resets itself to 0 when their respective counts reach 5.
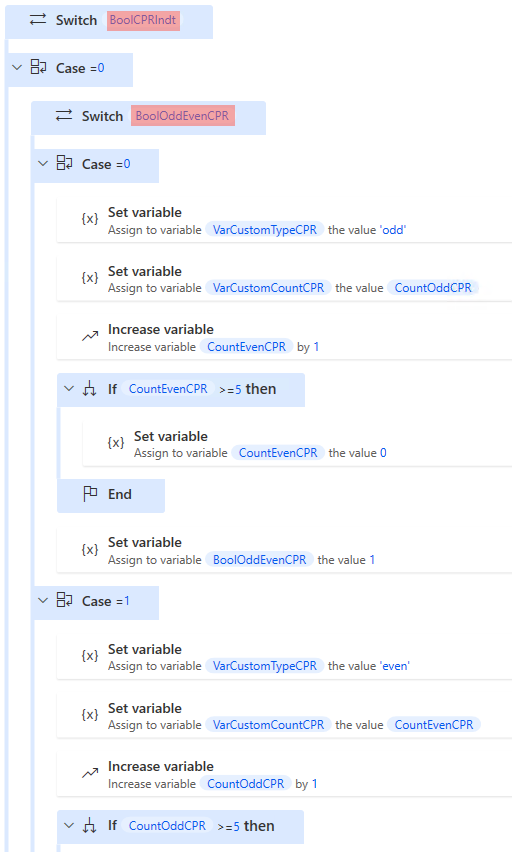
The custom selector for the citizen table looks like this.



