1. Introduction #
While structuring code is not typically considered important, it will become so when you scale your RPA project later. If you get new developers for one reason or another, they need to be able to read, understand, and maintain other people’s code. It is therefore easier if it is uniform and has a fixed structure that all developers adhere to within reasonable limits. It does not necessarily have to be written in stone, but the more uniform it is, the easier it should be to maintain.
Furthermore, when we work with processes, there is a natural division of steps in these, which you can follow a little in your code. This can help to collect documentation ( flow charts, description of the workflow, etc. ), and the code to resemble each other a little overall when held up against each other.
The most important parts of this will be a naming convention for variables, function separation in the code, and how to do debugging. These topics are described below. Furthermore, it is always a good idea to make comments continuously in your code about what is being done. This will not be reviewed, as it is a more general part of coding in general.
2. Variables #
2.1 Naming convention #
You don’t need a specific naming convention for everything, but overall it could look something like this. You can also have smaller rules that determine which naming convention applies in certain cases. If you take an Excel sheet and pull data from it, is it a DataExcel because it is data or an ExcelData because it comes from a business system?
| Variable name | Comment |
| BoolXYZ | For things that can only have two values ( true/false, 0/1, yes/no and the like ) |
| CountXYZ | Variables that count something ( Excel rows, amounts of runs in a loop, etc. ) |
| CredFagsystemUser CredFagsystemPassword | For credentials, so you can see what the different ones are used for ( e.g. CredOutlookUser ) |
| CurrentXYZ | Only used for loop items, can be anything from email to rows in excel etc. |
| DataXYZ | Only used for raw data, and typically used in a for each loop ( Data table, Excel sheet extraction, Emails from inbox and similar ), to find more specific data varXYZ that needs to be used. Always has priority for naming, if other rules could be used as well |
| DateXYZ | For date and datetime variables |
| EmailXYZ | Email-related ( to, from, body, signature, etc. ) |
| ErrorXYZ | Used only for error handling (see 3.2. Debugging below for example ) |
| FileXYZ | For variables related to files ( FilePathXYZ, FileName and similar ) |
| FolderXYZ | For variables related to folders ( FolderPathXYZ, FolderName and similar ) |
| JSONXYZ | Only used for JSON files |
| LstXYZ | Used for lists |
| ScriptError | Only used in this format as error handling for scripts |
| TimeXYZ | Variables that only have to do with time |
| VarXYZ* | Reserved to be used only for real data that is handled, i.e. for everything other than variables that are used for logic so that the robot can run, and decide on things. Typically extracted from a Data variable ( the content is typically personal data that needs to be used for something or other ). Always has priority for naming, if other rules could be used as well |
| ProgramXYZ | For variables that only have to do with a program and are used for some purpose therein ( for example ExcelFirstFreeRow, ExcelColumnName, SAPInstance, ExchangeUser ) |
* var is borrowed from C# programming, where this is an implied variable, where the compiler can choose the data type based on the contents of the variable. I use it to separate what are variables for logic, and what are actually data that are being handled.
This makes the variable section of the code easy to read, and quickly see what is what. Below is an example with explanations from a process, where you can quickly see what is what based on the naming. Please note that there is a list, which however belongs to the Error category, so here that rule is used rather than calling it LstError .
| BoolChecked | From the name, you can guess that this is used to see if something is checked or not. |
| CountPosts | A counter to check how many posts have been made |
| CredExchangeUser CredExchangePass | Common credential for some exchange mail |
| CurrentExcelRow | Some data used in a loop from an excel sheet |
| DataExcel | Data from an Excel sheet |
| DataPDF | Extract from a PDF |
| DateCurrent | Today’s date |
| EmailHTMLBody | Some HTML for an email body |
| ErrorLast ErrorList ErrorLocal | Standard debugging variables found in each process |
| ExcelCurrentRow ExcelFirstFreeRow ExcelFirstFreeColumn ExcelInstance | This is the ProgramXYZ rule, where we can see that these variables only have to do with Excel, and are only used here. |
| ExchangeConnection | An exchange connection |
| FilePDF FilePathReport FileName | Has to do with files |
| FlowLink | A variable that does not follow a specific naming convention, which is optional instead |
| FolderPathTempSave | Has to do with folders |
| VarCPR VarName WasLeader WasEmploymentDate | Some final data used in the process, which is almost always extracted from a Data variable. Notice that there is a date that falls under the var naming convention, as this is output data, and not just a date used for logic. |
2.2 Use the same name for variable during transformation #
To avoid creating too many variables that are not used for anything other than an intermediate station, the same variable name is used throughout the transformation of the content. This makes it possible to look up individual variables and see their transformation and use throughout the process. If you have too many intermediate stations, you will have to search for them every time you need to step forward or backward to see the transformation of the variable. With this rule, you can reduce the total number of variables, and in this way make the code more manageable.
The bad example looks like this, which we are trying to avoid with the rule. Below we extract data from a DataPDF variable, where we take multiple extracts.
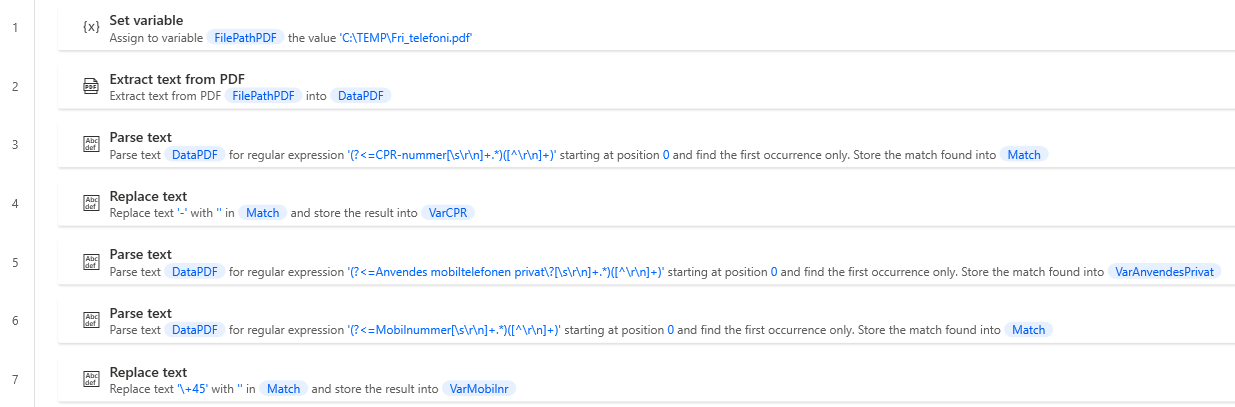
When searching for VarCPR, we can only see that it comes from Match , and we will then have to look this up to find out where it comes from. In addition, we will be able to see several different data pulled from this. This can create confusion when trying to read the code.
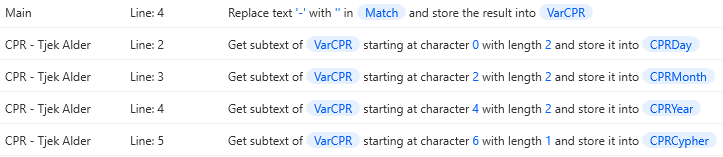
By searching on Match ., we can further see that many different variables are created from here.

The good example would look like this. In this case, it makes sense to have the intermediate station, since we are pulling different data from the same place. You can see how VarCPR and VarMobilnr are transformed, without the intermediate being called something else.
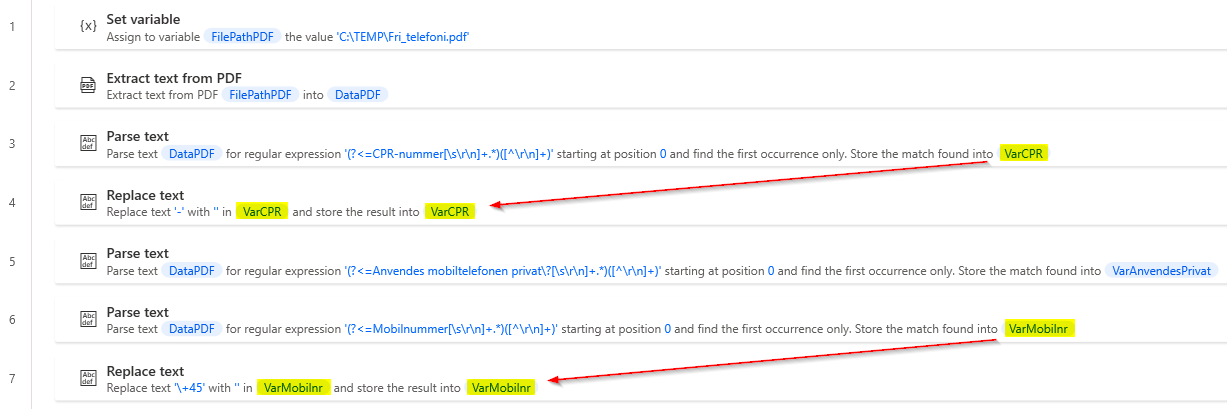
For example, a search for VarCPR would look like this, where we can see that it originates from DataPDF and how it is transformed in the process.
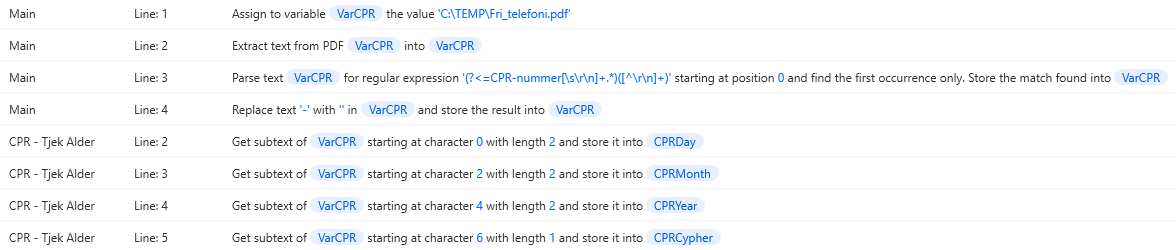
If you only need to use one variable from a data extract, you can call it specifically what the final product is called instead. DataPDF will be redundant, as it will not be used as anything more than a staging area. If you do a search on the variable, it will look like this instead, where you can see the entire inheritance down to the file it originated from.
2.3 Custom objects #
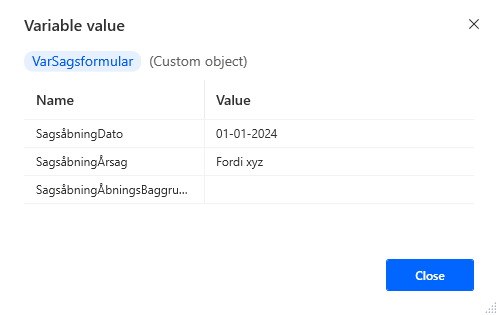
For example, when filling out forms, you can end up having extra variables that are only used for this one purpose. In such cases, you can create a custom object to contain these. This can help with readability, by again reducing the amount of variables that you need to be able to see what they are used for and or come from. Example here from Power Automate Desktop.
Creating a custom object is in the format %{‘Navn’:’value’}% which is comma separated if multiple values are needed.
It will look like this when it is run.
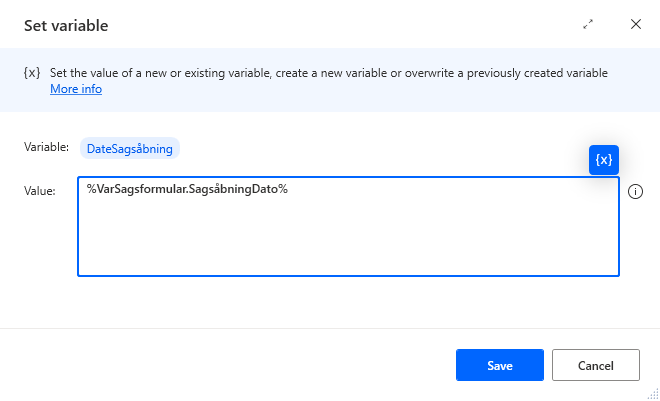
If you need to retrieve individual variables, it can be done as follows.
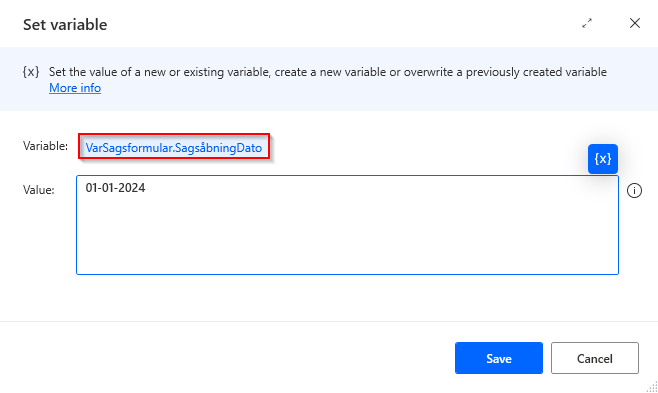
If you want to override existing variables, do this:
2.4 Avoid magic numbers / strings #
In programming languages, there is a term called magic numbers , magic strings, and the like. These can be a unique value that is not explained or have multiple occurrences. Most often, these can be replaced with a named variable to make their purpose visible. It can be difficult to maintain code, especially other people’s, if there are many such occurrences. Therefore, you should avoid using them where possible.
A typical scenario I often come across is a CurrentItem that continuously inserts values in a for each loop. In the example below, you can’t directly know what CurrentRowExcel[5] is.
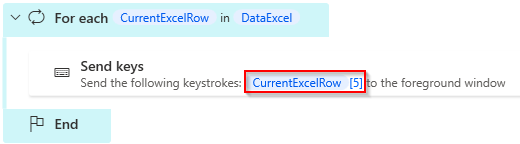
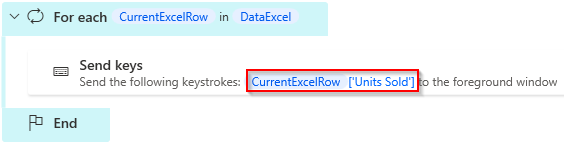
In cases with Excel sheets / data tables, it is possible in e.g. Power Automate Desktop to use the first line as column headers. In this case, you can demystify the variable as below. In other cases, a solution may be to create a named variable to use instead.
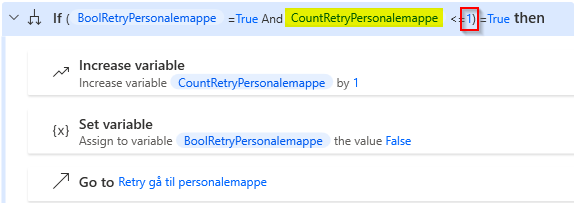
Another example might look like this, where 1 is the maximum number of retries. In this case, the number is not entirely magical, as you can see from the previous variable what it might be/is used for. In this case, you can argue for either leaving it or putting it in as a variable instead.
3. Functional division of the code #
3.1 RPA process structure #
The thoughts and experiences reviewed in the next sections are based on the fact that a standard RPA process/code can almost always follow these steps.

Initialize will always be the first step that runs. Typically it is some code that is the same between processes, for example creating a temp folder to work in, setting fixed variables, setting registry keys, etc.
Find data is the step where we retrieve our data basis for the run. This can be, for example, loading an excel sheet from a file path or an email with content that forms the data basis for the run. In this step, you can also check whether there is actually data for the process or it can turn off the robot again.
Start programs if there is data for the run, in this step you will start logging in and go to the images that the robot will work from.
Loop data will be the loop where you go through all the data and perform the actual RPA process.
Exit/Cleanup will be a cleanup step of the code, where you close your open programs, delete your temp folder, notify the process owner, log profit realization, and the like.
You can also use this technique to make maintenance and debugging easier. An example is filling out forms ( invoices, journaling for a business system, etc.) . Here you should have a function to find all variables that need to be used, and one for filling out the form itself. The debugging part is discussed in more depth in section 4. In short, by dividing, you can already skip the form filling if you do not find all the required variables. Instead of the robot trying to fill out the form, and then crashing because it is missing a variable. Errors that occur during filling will also typically be selector related and not logic (unless the user can use API calls ) .
The maintenance part also becomes easier, since you have divided the code if changes are made to one part or another. This is in addition to the fact that it may be easier for other developers to familiarize themselves with the code when it is divided in this way. An example could be that you change the subject system to pay invoices, i.e. the form part must be changed, but the variables are still the same. Furthermore, it is conceivable that you sometimes have similar processes where you would like to copy-paste the form part over, which is filled with variables from another source.

3.2 Function division example #
You can split your code into functions to make it more readable. You can also have a numbering convention if you feel the need. It can be difficult to figure out when to split code into a new function rather than writing a function. If you can, and it makes sense, it is almost always better to split code into multiple functions. This makes it easier to maintain, and helps keep it structured so that others can also get to grips with the process quickly.
An example of dividing code might look like this. As a rule, you could have all the code in 20.10 – Loop, in the order it is to be run, but that would be a very large function. If it needs to be debugged or corrected, there is also a greater chance of errors and oversights when working directly with it. By splitting it into several functions, it is more readable, and you will have better control over the code, as there is less to deal with. If a robot fails in, for example , 20.30 – Create variables from data , we already know what the robot is trying to do. So we don’t need the code directly line by line to see what is happening and be able to distinguish when it is doing something else irrelevant to the error.

Furthermore, you can validate whether the things that will be used for the next part of the process are in place continuously in the functions. This can make debugging easier, as you can then expect that an error that occurs somewhere is probably also where the error actually occurs. Below is an example of 20.30 – Create variables from data , where we also validate that the variables we are trying to find also exist when we have tried to extract them. If you did not validate this, you could get an error in 20.40 – Upload file to personnel folder , because a CPR number is missing for employee lookup. This will be an error that occurs in 20.30 , which will however only be discovered in 20.40 when it is to be used.

Furthermore, you can number each function so that you can see the order in which they are used in the code. I use a small numbering convention myself as described below.
| Main | Only runs functions, as little logic as possible, so you can quickly get an overview of the process. |
| Global Error Handler | Handles errors, see debugging section |
| 00.10 | All the little things that need to be done before the robot can start, typically variables, credentials and other things that are only set once |
| 99.99 – Exit | Cleanup after driving |
| 10.xx | All the major things that need to be in place before the robot can start the process, typically login to programs, and retrieve raw data for the run, etc. |
| 20.10 – Loop | Runs data extraction through typically from 10.xx. Works like with Main , which only runs functions, and as little logic as possible. This is to create a quick overview of how the flow is in a loop. 20.10 is reserved for this purpose, and 20.xx will be subflows belonging to this. |
| xx.xx | Everything else that comes, every time a new sub-process needs to be done, the number in the sequence increases. Things that belong together stay together that way, and other things get separated. |
Please note that at the time of writing, you cannot move your functions up and down the list in Power Automate Desktop , which is why there are spaces between the numbers. This means that additional functions can be inserted between existing ones later if the need arises, which are then still readable according to the order. In the example below, you can still calculate that 10.30 is run after 10.20, even though it appears at the bottom of the list.
Below is an example where you can see that 20.xx belong together, where you can see the order. Furthermore, you can see that 30.10 is a stand-alone function.
| Main | Only runs functions, as little logic as possible |
| Global Error Handler | Handles errors, see debugging section |
| 00.10 – Initialize | Everything that needs to be done before the robot can actually start, typically variables, credentials and other things that are only set once |
| 99.99 – Exit | Cleanup after driving |
| 10.10 – Get Mail | Download data for the run |
| 10.20 – Log in to SAP | Login to the program to be used |
| 20.10 – Loop | Loop that runs through the data |
| 20.20 – Retrieve data from email | Subprocess in 20.10 – Loop |
| 20.30 – Upload PDF in SAP | Subprocess in 20.10 – Loop |
| 20.40 – End treatment | Subprocess in 20.10 – Loop |
| 30.10 – Advises process owner | Send email to process owner after loop is complete |
4. Debugging #
Debugging is typically a tedious task that can be difficult to implement. I have chosen to standardize mine so that it can be included in my template for new processes. It is built for Power Automate Desktop, but it should be able to do similar things in other software. Debugging data is created continuously while the robot is running, and is sent out when the robot crashes, and in the event of minor errors, even if the robot has finished running. After a run, you can send the log to a shared mailbox among the RPA team, so that everyone has access in case of illness/vacation.
Explanation follows below, but overall three variables are used as shown, and a handful of Error Blocks. In Main nothing else is done but to run subflows, and this has an Error Block , which runs my Global Error Handler if a subflow is hit by an error. This Error Block always triggers on critical errors, even if it is a subflow within a subflow that crashes the process. Every place in the code where an error will potentially crash the process, there is an Error Block that sets the variable %ErrorLocal% . This was written by myself, and gives a clue as to what the error might be. So in terms of understanding, you can think of it as:
- An error occurs that crashes the process, an Error Block outside Main sets an %ErrorLocal% with a possible explanation for the error.
- The Error Block in the Main trigger subsequently runs the Global Error Handler subflow, which retrieves the PAD’s own last error, and sends the entire error report to the developer.
- As a note, debugging is done in HTML, as it is easier to insert as a list. The body of the email is written as – ” PAD Error – %ErrorLast%< br><br> Local Error – %ErrorLocal%< br><br> List of errors when running:< br> %ErrorList%“
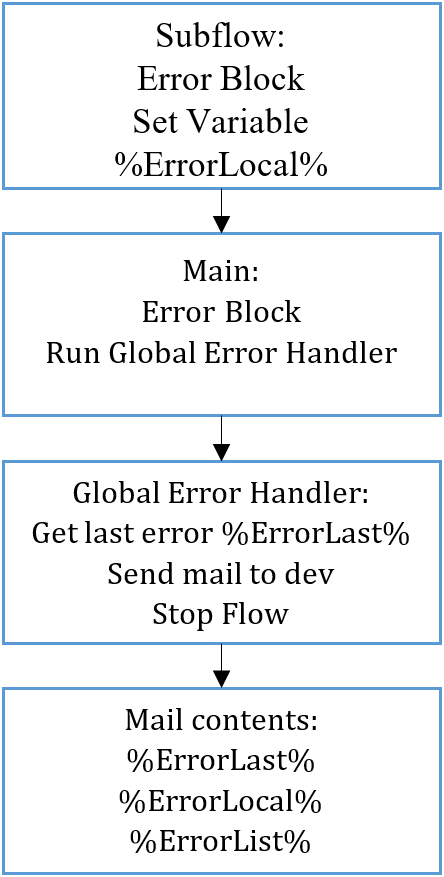
The three variables I use for debugging are described:
ErrorLast the error that PAD itself reports when it crashes. Logged in Global Error Handler if the robot crashes completely.
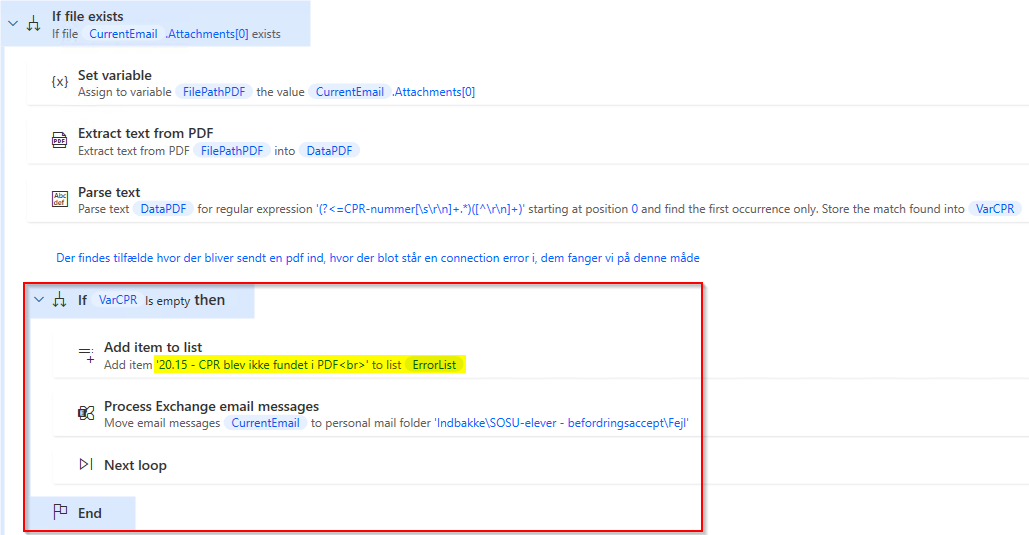
ErrorList contains small errors where the robot can continue running afterwards. An error can be like the one below, where we check that we have received a variable that is necessary for the rest of the run. If this is not the case, we log the error to the list and take the next run in the loop instead. This prevents the robot from continuing and crashing later in the process. The list can then be used to find out if any code needs to be adjusted, or if it is actually an error that needs to be taken out for manual processing in the future. It can sometimes also show something that was not expected and needs to be addressed.
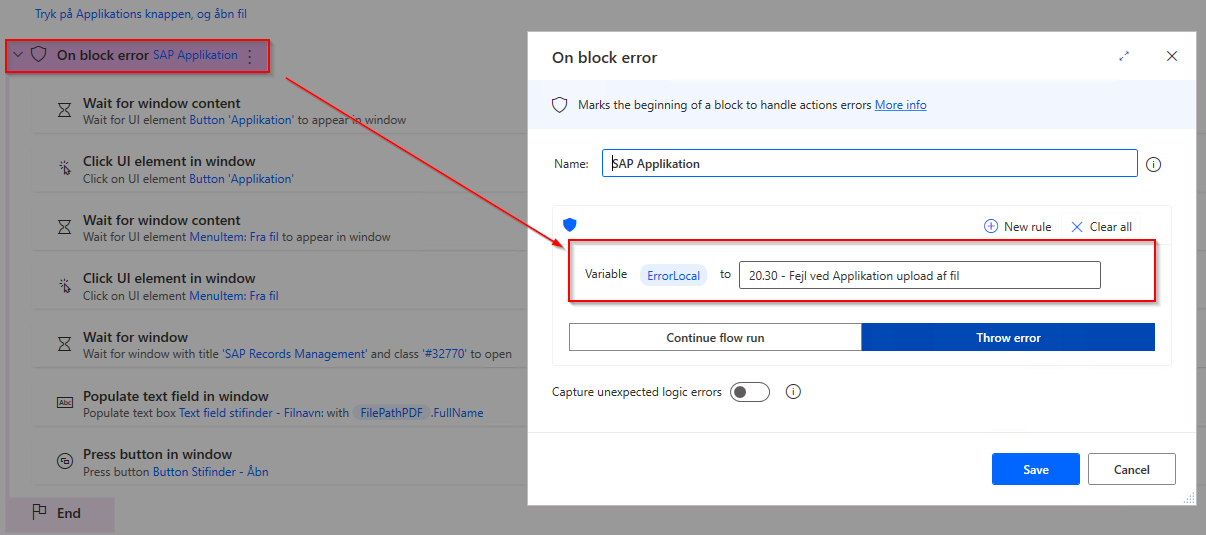
ErrorLocal an expected error that can happen, where I have written something more descriptive of what it is. Typically I put these as an On block error around code that does a small part of a function. In the example here there is a block above to handle if it can’t get to the right image, and also a block below if it can’t fill out the rest of the form. That way I get both PAD’s error about which action failed, but also what the robot was trying when it happened. Only logged if the robot crashes completely, and can be set to individual actions too.
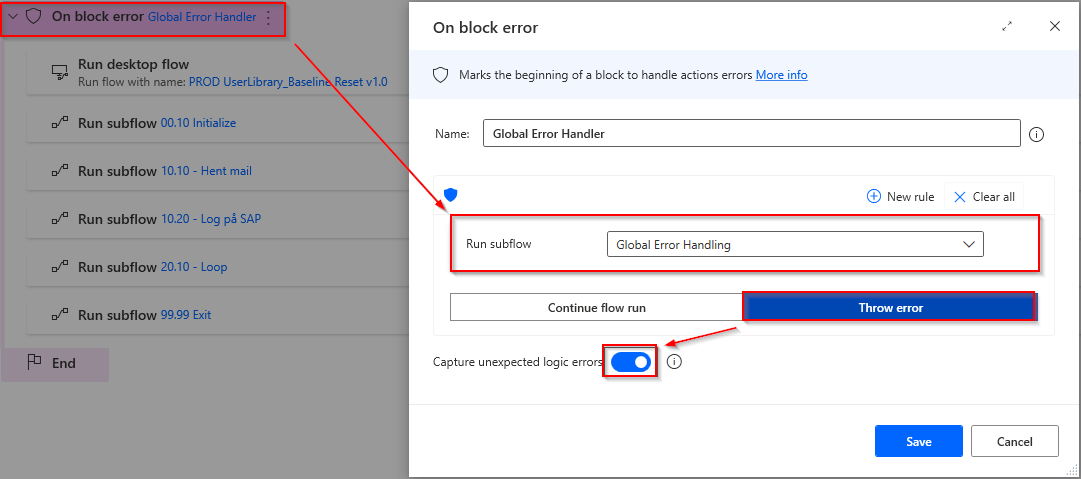
On Main is the block that controls the Global Error Handler which is only called if an error completely crashes the process. It triggers no matter which subflow makes the error. Even if a subflow is not in Main , it still triggers on critical errors if a subflow is part of the subflows below (this inheritance continues infinitely in levels of subflows) . Example 20.10 – Loop runs subflows that are not run in Main , if these make errors, the block in Main still triggers because they belong to 20.10 – Loop . If you need to run the test process in PAD without this debug, you can turn it off by deactivating the block.
The Global Error Handler itself looks like this. Here, all Error handling is sent in the email, which is done via HTML code in the body of the email – ” PAD Error – %ErrorLast%< br><br> Local Error – %ErrorLocal%< br><br> List of errors when running:< br> %ErrorList% “
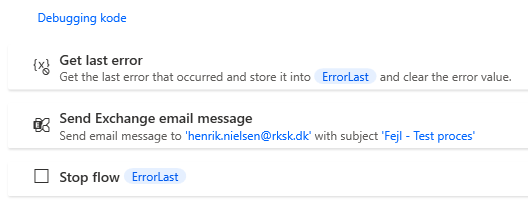
Even after a successful run, the robot sends the ErrorList to the developers if it is not empty. This is to be able to review whether any code needs to be changed or whether such errors should actually be taken out for manual processing by a human in the future instead. In 99.99 – Exit this is done in my own code.
A return email can look like this for example in the event of a crash. From this it can be concluded that the robot was clicking into a personnel folder, where it could not fill in a text field on the way. Furthermore, we can see that it has had two minor mistakes that it has skipped. Either an employee number or a date was missing, which was needed to be able to make the run.
” PAD Error – Underflow: 20.30 – SAP save file in personnel folder, action: 4, action name: Fill text field in window Error message: Could not write in text field (text field not found) More information: {}
Local Error – 20.30 – Could not navigate the personnel folder
List of errors when running:
20.20 – Could not find employee number associated with CPR “111111-5555” or Date “” in SQL extract
20.20 – Did not find employee number associated with CPR “555555-1111” or Date “20-03-2024” when SQL extracting “
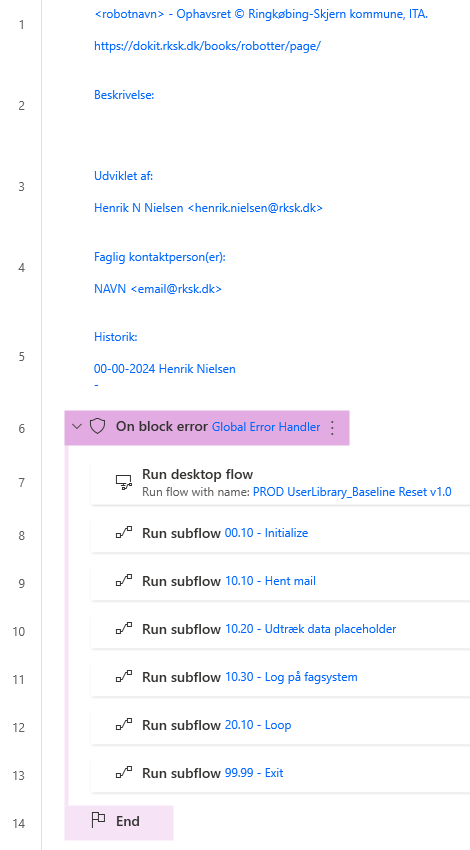
5. Code template #
In many cases it is easiest to create a template that can be copied when creating new processes. This can contain functions, variables, debugging, etc. that are always or almost always used across processes. Typically I have the following, in addition to a text template for documentation at the beginning of Main . This can also help make things more consistent, across developers or your own processes.
| Main | Only running functions, as little logic as possible, and documentation at the top |
| Global Error Handler | Standard debugging I use |
| 00.10 – Initialize | Creates a temp save folder, a Count variable, list for errors, and retrieves credentials to send debugging information, as well as other things that are only set once. |
| 99.99 – Exit | Logging execution in SQL table, sending debugging if there were errors in ErrorList, and deleting the temp folder |
| 10.10 – Get email | Many of my processes start by retrieving an email, which is the data basis for the rest of the execution. Generally, it can also be a “Retrieve data” subflow |
| 10.20 – Extract data placeholder | Placeholder if there is a need to extract some data before the loop starts |
| 10.30 – Log in to the subject system | A placeholder if there is a need to log in to something and set to a default view before a loop is run |
| 20.10 – Loop | Runs a foreach on the data foundation and calls its subflows in a specific order |
| 20.20 – Extract data placeholder | A placeholder for extracting data to be used in the loop. This sets any variables that will be used in the rest of the loop. |
| 20.21 – Extract data placeholder | Blank placeholder if you need to extract extra data and need a subflow for 20.20 |
This is how Main looks, where some of the documentation can be filled out or linked to an internal system.