1. Introduktion #
Hvorimod strukturering af kode ikke typisk bliver anset som vigtigt, vil det blive det, når man skalerer sit RPA-projekt op senere. Får man nye udviklere af den ene eller anden årsag, skal disse også kunne læse, forstå og vedligeholde andres kode. Det er derfor nemmere hvis det er ensartet, så man har en fast struktur, alle udviklerne holder sig til indenfor rimelighedens grænser. Det er ikke nødvendigvis noget der skal stå skrevet i sten, men jo mere ensartet det er, jo nemmere burde det være at vedligeholde.
Yderligere når vi arbejder med processer, så er der en naturlige opdeling af trin i disse, som man kan gøre lidt efter i sin kode. Dette kan være med til at samle dokumentation (flow-charts, beskrivelse af arbejdsgangen m.m.), og koden til at ligne hinanden lidt overordnet, når de holdes op mod hinanden.
De vigtigste dele af dette, vil være en navnekonvention til variabler, funktionsopdeling i koden, og hvordan man laver debugging. Disse emner beskrives nedenfor. Yderligere er det altid en god ide, at lave kommentarer løbende i sin kode, om hvad der bliver foretaget. Dette bliver ikke gennemgået, da det er en mere overordnet del af kodning generelt.
2. Variabler #
2.1 Navnekonvention #
Man behøver ikke en specifik navngivning til alt, men overordnet kan det eksempelvis se således ud. Man kan yderligere have mindre regler, der bestemmer hvilken navnekonvention der gælder i visse tilfælde. Hvis man tager et Excel-ark, og hiver data ud fra, er det så en DataExcel fordi det er data eller en ExcelData fordi det kommer fra et fagsystem?
| Variable navn | Kommentar |
| BoolXYZ | Til ting der kun kan have to værdier (true/false, 0/1, ja/nej og lignende) |
| CountXYZ | Variabler der tæller et eller andet (Excel rækker, mængder af kørsler i et loop m.m.) |
| CredFagsystemUser CredFagsystemPassword | Til credentials, så man kan se hvad de forskellige bruges til også (eks CredOutlookUser) |
| CurrentXYZ | Bruges kun til loop items, kan være alt fra mail til row i excel m.m. |
| DataXYZ | Bruges kun til rå data, og bruges typisk i et for each loop (Datatabel, Excel-ark udtræk, Emails fra indbakke og lignende), til at finde mere specifikt data varXYZ som skal bruges. Har altid prioritet til navngivning, hvis andre regler kunne bruges også |
| DateXYZ | Til date og datetime variabler |
| EmailXYZ | Der har med email at gøre (til, fra, body, signatur m.m.) |
| ErrorXYZ | Bruges kun til fejlhåndtering (se 3.2. Debugging nedenfor for eksempel) |
| FileXYZ | Til variabler der har med filer at gøre (FilePathXYZ, FileName og lignende) |
| FolderXYZ | Til variabler der har med mapper at gøre (FolderPathXYZ, FolderName og lignende) |
| JSONXYZ | Bruges kun til JSON filer |
| LstXYZ | Bruges til lister |
| ScriptError | Bruges kun i dette format, som error håndtering til scripts |
| TimeXYZ | Variabler der kun har med tid at gøre |
| VarXYZ* | Reserveret til kun at blive brugt til reelle data der håndteres, dvs til alt andet end variabler som bruges til logik så robotten kan køre, og tage stilling til ting. Typisk udtrukket fra en Data variabel (indholdet er typisk persondata der skal bruges til et eller andet). Har altid prioritet til navngivning, hvis andre regler kunne bruges også |
| ProgramXYZ | Til variabler der kun har med et program at gøre, og bruges til et eller andet formål heri (eksempelvis ExcelFirstFreeRow, ExcelColumnName, SAPInstance, ExchangeUser) |
* var er lånt fra C# programmering, hvor denne er en underforstået variabel, hvor compileren selv kan vælge datatypen baseret på indholdet i variablen. Jeg bruger det for at adskille hvad der er variabler til logik, og hvad der reelt er data der bliver håndteret.
Dette gør variabelsektionen af koden nem at læse, og hurtigt kunne se hvad der er hvad. Herunder et eksempel med forklaringer fra en proces, hvor man ud fra navngivningen hurtigt kan skimte hvad der er hvad. Vær opmærksom på at der findes en list, der dog hører under Error kategorien, så her bruges den regel frem for at kalde den LstError.
| BoolTjekket | Ud fra navnet, kan man gætte sig til at denne bruges til se om noget er tjekket eller ej |
| CountOpslag | En tæller til at tjekke hvor mange opslag der er lavet |
| CredExchangeUser CredExchangePass | Almindelig credential til noget exchange mail |
| CurrentExcelRow | Noget data der bruges i et loop ud fra et excel ark |
| DataExcel | Data fra et Excel ark |
| DataPDF | Udtræk fra en PDF |
| DateCurrent | Dagens dato |
| EmailHTMLBody | Noget HTML til en email body |
| ErrorLast ErrorList ErrorLocal | Standard debugging variabler der findes i hver proces |
| ExcelCurrentRow ExcelFirstFreeRow ExcelFirstFreeColumn ExcelInstance | Det her er ProgramXYZ reglen, hvor vi kan se at disse variabler kun har med Excel at gøre, og bruges kun heri. |
| ExchangeConnection | En exchange forbindelse |
| FilePDF FilePathRapport FileName | Har med filer at gøre |
| FlowLink | En variabel som ikke hører under en specifik navnekonvention, som er valgfri i stedet |
| FolderPathTempSave | Har med mapper at gøre |
| VarCPR VarNavn VarLeder VarAnsættelsesDato | Noget slut data der bruges i processen, som næsten altid er trukket ud fra en Data-variabel. Læg mærke til at der er en dato, som hører under var navnekonventionen, da denne er output data, og ikke bare en dato der bruges til logik. |
2.2 Brug samme navn til variabel under transformation #
For at undgå at der laves for mange variabler, der ikke bruges til andet end en mellemstation, bruges samme variabelnavn igennem transformation af indholdet. Dette gør det muligt at slå enkelte variabler op, og se deres transformeringen, og brugen igennem processen. Har man for mange mellemstationer med, vil man skulle søge disse frem hver gang man skal et trin frem eller tilbage, for at se transformeringen af variablen. Med denne regel kan man nedjustere totalmængden af variabler, og på den måde gøre koden mere overskuelig.
Det dårlige eksempel ser således ud, som vi forsøger at undgå med reglen. Herunder trækker vi data fra en DataPDF variabel, hvor vi tager flere udtræk ud.
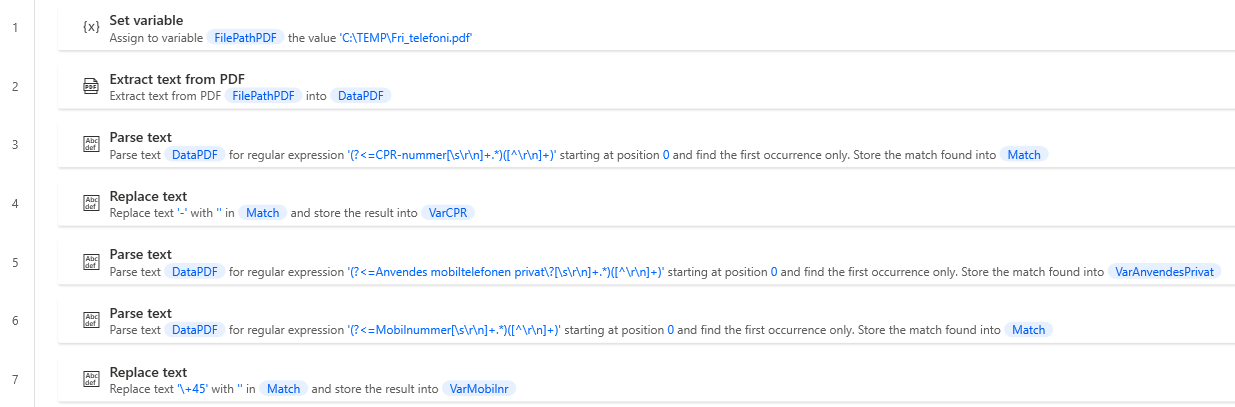
Ved en søgning på VarCPR kan vi kun se at den stammer fra Match, og vi vil herefter skulle slå denne op, for at finde ud af hvor den kommer fra. Hertil vil vi så kunne se flere forskellige data der trækkes fra denne. Dette kan skabe forvirring, når man forsøger at læse koden.
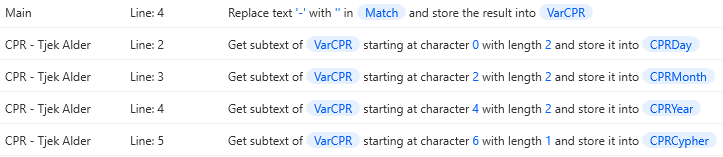
Ved søgning på Match., kan vi så yderligere se at det er mange forskellige variabler der laves herfra.

Det gode eksempel vil se således ud. I dette tilfælde giver det mening af have mellemstationen, da vi trækker forskellige data det samme sted fra. Man kan se hvordan VarCPR og VarMobilnr bliver transformeret, uden at mellemledende hedder noget andet.
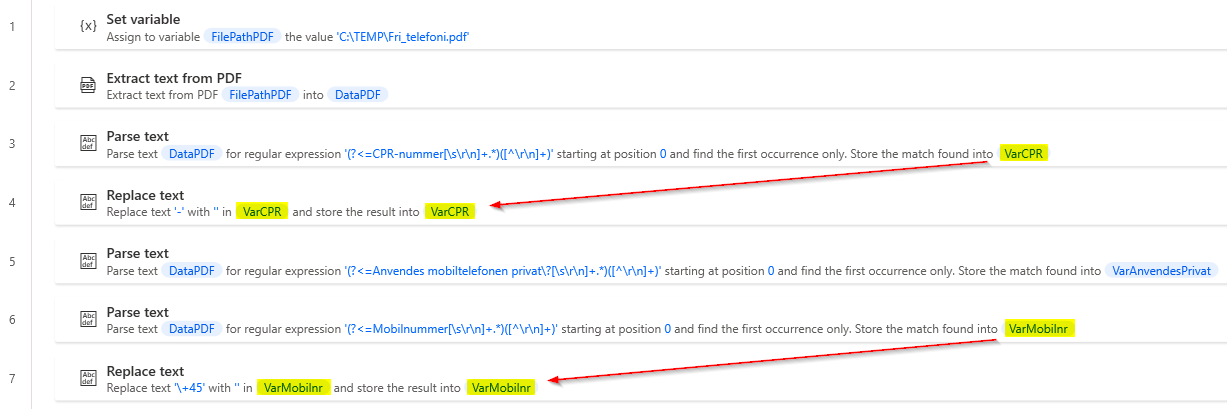
En søgning på VarCPR vil eksempelvis se således ud, hvor vi kan se at den stammer fra DataPDF, og hvordan den bliver transformeret processen.
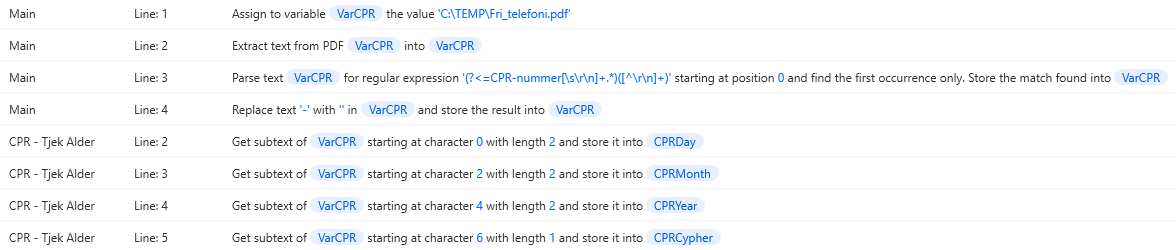
Hvis man kun skal bruge én variabel fra et dataudtræk, kan man kalde det specifikt hvad slutproduktet hedder i stedet. DataPDF vil være overflødig, da denne ikke vil bruges som andet end en mellemstation. Hvis man laver en søgning på variablen, vil den se således ud i stedet, hvor man kan se hele nedarvningen ned til filen den stammer fra.
2.3 Custom object #
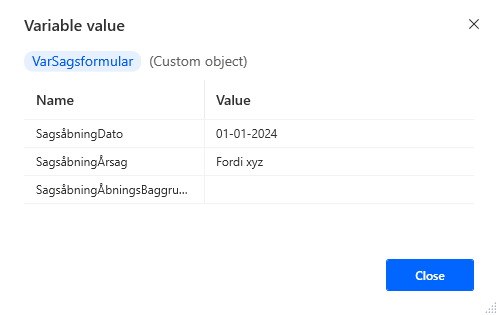
Ved eksempelvis formular udfyldninger, kan man ende med at have ekstra mange variabler, der kun bruges til dette ene formål. I sådanne tilfælde kan man lave et custom object til at indeholde disse. Dette kan hjælpe med læsbarheden, ved igen at reducere mængden af variabler, man skal kunne se hvad bruges til og eller stammer fra. Eksempel her fra Power Automate Desktop.
Oprettelse af et custom object, er i formattet %{‘Navn’:’value’}% som komma separeres hvis der skal flere værdier med.
Det vil se således ud når det er kørt.
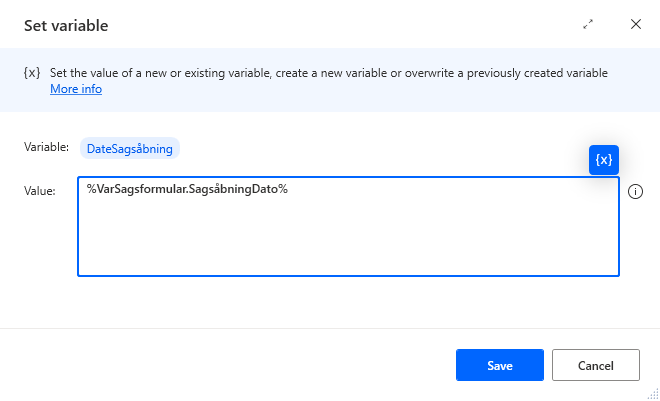
Skal man hente enkelte variabler ud, kan det gøres således.
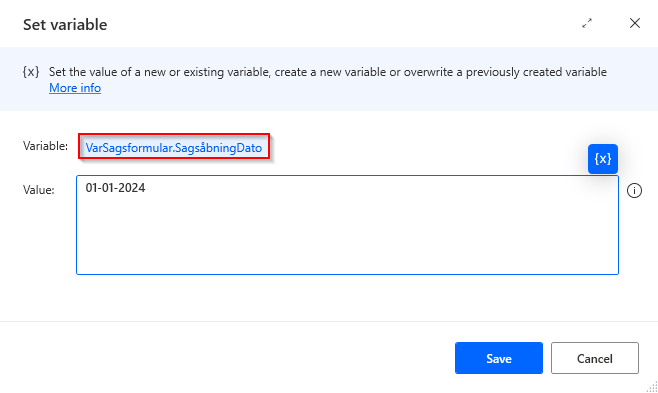
Vil man overskride eksisterende variabler gøres det således:
2.4 Undgå magic numbers / strings #
I programmeringssprog har man et udtryk der hedder magic numbers, magic strings og lignende. Disse kan være en unik værdi som ikke er forklaret eller har flere forekomster. Oftest kan disse erstattes med en navngiven variabel, for at synliggøre deres formål. Det kan være svært at vedligeholde kode, specielt andres, hvis der er mange af sådanne forekomster. Derfor bør man lade være med at benytte dem, hvor det er muligt.
Et typisk scenarie jeg selv falder over tit, er en CurrentItem som indsætter værdier løbende i et for each loop. I eksemplet nedenfor kan man ikke direkte vide, hvad CurrentRowExcel[5] er.
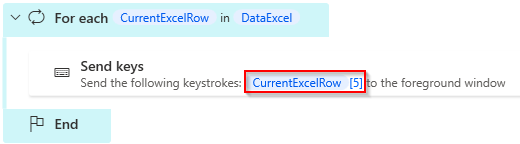
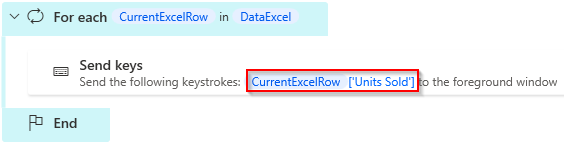
I tilfælde med Excel-ark / data tables, er det muligt i eksempelvis Power Automate Desktop, at bruge første linje som kolonne headers. I dette tilfælde kan man afmystificere variablen som nedstående. I andre tilfælde kan en løsning være, at lave en navngiven variabel man bruger i stedet.
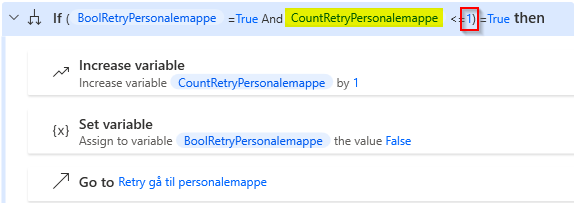
Et andet eksempel kan se således ud, hvor 1 er maksimalt antal retries. I dette tilfælde er tallet ikke helt magisk, da man kan se ud fra tidligere variabel, hvad den muligvis er/bruges til. I dette tilfælde kan man argumentere for både at lade den stå eller sætte den ind som variabel i stedet.
3. Funktionsopdeling af koden #
3.1 RPA-processer opbygning #
De tanker og erfaringer som gennemgås i de næste afsnit bygger på, at en standard RPA-proces/kode næsten altid kan følge disse trin.

Initialize vil altid være det første trin som kører. Typisk er det noget kode der ens imellem processer, eksempelvis oprettelse af temp-mappe til at arbejde i, indstilling af faste variabler, registreringsnøgler som sættes, m.m.
Find data er det trin hvor vi henter vores datagrundlag for kørslen. Dette kan eksempelvis være indlæsning af et excel-ark fra en filsti eller en mail med indhold som laver datagrundlaget for kørslen. I dette trin kan man også have et tjek på, om der reelt er data til processen eller den kan slukke robotten igen.
Start programmer såfremt der er data til kørslen, vil man i dette trin begynde at logge ind, og gå til de billeder som robotten skal arbejde fra.
Loop data vil være det loop, hvor man går igennem alt data, og udfører den reelle RPA-proces.
Exit/Cleanup vil være et oprydningstrin af koden, hvor man lukker sine åbne programmer ned, sletter sin temp mappe, underretter procesejer, logger gevinstrealisering, og lignende.
Man kan yderligere benytte denne tækning til at gøre vedligehold og debugging lettere. Et eksempel er omkring udfyldelse af formularer (fakturaer, journalisering til fagsystem m.m). Her bør man have en funktion til at finde alle variabler som skal bruges, og en til selve udfyldelsen af formularen. Debugging delen bliver gennemgået mere dybdegående i afsnit 4. Kort fortalt så kan man ved opdelingen, allerede springe formular udfyldelsen over, hvis man ikke finder alle de påkrævede variabler. I stedet for at robotten forsøger at udfylde formularen, og så crasher fordi den mangler en variabel. Fejl der sker ved udfyldelsen vil også typisk være selector relateret og ikke logik (medmindre kan bruger API-kald).
Vedligeholdsdelen bliver også nemmere, da man har opdelt koden, hvis der sker ændringer i den ene eller anden del. Dette er foruden at det kan være nemmere for andre udviklere, at sætte sig ind i koden når det er opdelt på denne måde. Et eksempel kan være man skifter fagsystem til at betale fakturaer, dvs. formular delen skal ændres, men variablerne er forsat de samme. Yderligere kan det tænkes man ind imellem har lignende processer, hvor man gerne vil copy-paste formular delen over, som udfyldes med variabler fra en anden kilde.

3.2 Funktionsopdeling eksempel #
Man kan funktionsopdele sin kode, så den bliver mere læselig. Hertil kan også have en nummereringskonvention, hvis man føler behovet. Det kan være svært, at finde ud af hvornår man skal splitte kode ud, til en ny funktion fremfor at skrive en funktion. Hvis man kan, og det giver mening, er det næsten altid bedre at splitte kode op i flere funktioner. Dette gør det nemmere at vedligeholde, og hjælper med at holde det struktureret, så andre også kan sætte sig ind i processen hurtigt.
Et eksempel på opdeling af kode, kan se således ud. I reglen kunne man godt have alt koden stående i 20.10 – Loop, i den rækkefølge det skal køres, det ville dog blive en meget stor funktion. Hvis det skal debugges eller rettes i, er der også større chance for fejl, og forglemmelser når man arbejder direkte med det. Ved at splitte det ud i flere funktioner, er det mere læsbart, og man vil have bedre styr på koden, da der er mindre at forholde sig til. Hvis en robot fejler i eksempelvis 20.30 – Lav variabler fra data, ved vi allerede hvad robotten prøver på. Vi behøver altså ikke direkte koden linje for linje, for at se hvad der sker, og kunne skelne hvornår den laver noget andet irrelevant til fejlen.

Yderligere kan man validere om de ting, som skal bruges til næste del af processen, er på plads løbende i funktionerne. Dette kan gøre debugging lettere, da man så kan forvente, at en fejl der sker et sted, nok også er der hvor fejlen reelt sker. Herunder er der et eksempel på 20.30 – Lav variabler fra data, hvor vi også validere at de variabler vi forsøger at finde, også eksisterer når vi har forsøgt at trække dem ud. Hvis man ikke validerede dette, kunne man få en fejl i 20.40 – Upload fil til personalemappe, fordi et CPR-nummer mangler til opslag af medarbejder. Det vil være en fejl der sker i 20.30, som dog først bliver opdaget i 20.40 når den skal bruges.

Endvidere kan man nummerere hver funktion, så man kan se hvilken rækkefølge de bruges i koden. Jeg bruger selv en lille nummereringskonvention som beskrevet nedenfor.
| Main | Kører kun funktioner, så lidt logik som muligt, så man hurtigt kan danne et overblik over processen. |
| Global Error Handler | Tager sig af fejl, se debugging afsnit |
| 00.10 | Alle småting der skal laves, før robotten kan gå i gang, typisk variabler, credentials og andre ting der kun sættes én gang |
| 99.99 – Exit | Cleanup efter kørsel |
| 10.xx | Alle de større ting der skal være på plads før robotten kan starte processen, typisk login til programmer, og hente rådata til kørslen m.m. |
| 20.10 – Loop | Kører data udtræk igennem typisk fra 10.xx. Fungerer ligesom med Main, som kun kører funktioner, og så lidt logik som muligt. Dette for at skabe hurtigt overblik, om hvordan flowet er i et loop. 20.10 er reserveret til dette formål, og 20.xx vil være subflows tilhørende denne. |
| xx.xx | Alt det andet der kommer, hver gang en ny delproces skal gøres øges tallet i rækkefølgen. Ting der hører sammen, forbliver sammen på den måde, og andet bliver adskilt. |
Vær opmærksom på at i skrivende stund, kan man ikke flytte sine funktioner op og ned på listen i Power Automate Desktop, derfor er der rum imellem tallene. Dette gør at der senere kan indskydes ekstra funktioner mellem eksisterende hvis behovet opstår, som så forsat er læsbare ifht rækkefølgen. I eksemplet herunder kan man forsat regne ud, at 10.30 køres efter 10.20, selvom den fremgår nederst på listen.
Herunder er der et eksempel, hvor man kan se at 20.xx hører sammen, hvor man kan se rækkefølgen. Yderligere kan man se at 30.10 er en enkeltstående funktion.
| Main | Kører kun funktioner, så lidt logik som muligt |
| Global Error Handler | Tager sig af fejl, se debugging afsnit |
| 00.10 – Initialize | Alt hvad der skal laves før robotten reelt kan gå i gang, typisk variabler, credentials og andre ting der kun sættes en gang |
| 99.99 – Exit | Cleanup efter kørsel |
| 10.10 – Hent Mail | Hent af data til kørslen |
| 10.20 – Log på SAP | Login til program der skal bruges |
| 20.10 – Loop | Loop der kører dataen igennem |
| 20.20 – Hent data fra mail | Delproces i 20.10 – Loop |
| 20.30 – Upload PDF i SAP | Delproces i 20.10 – Loop |
| 20.40 – Afslut behandling | Delproces i 20.10 – Loop |
| 30.10 – Adviser procesejer | Send mail til procesejer efter loopet er færdig |
4. Debugging #
Debugging er typisk en træls opgave, som kan være svær at implementere. Jeg har valgt at standardisere min, så den kan være med i min skabelon til nye processer. Den er bygget til Power Automate Desktop, dog burde den kunne lave lignende i andet software. Data til debugging laves løbende imens robotten køres, og sendes ud ved et crash af robotten, og ved mindre fejl også hvis robotten kørte helt færdig. Man kan efter en endt kørsel, sende loggen til en delt postkasse mellem RPA-teamet, så alle har adgang i tilfælde af sygdom/ferie.
Forklaring følger herunder, men overordnet bruges der tre variabler som vist, og en håndfuld Error Blocks. I Main laves intet andet end at køre subflows, og denne har en Error Block, som kører min Global Error Handler, hvis et subflow bliver ramt af en error. Denne Error Block trigger altid ved kritiske fejl, også selvom det er et subflow i et subflow der crasher processen. Hvert sted i koden, hvor en error vil crashe processen potentielt, sidder der en Error Block som sætter variablen %ErrorLocal%. Denne er skrevet ind af mig selv, og giver et fingerpeg om hvad fejlen kan være. Så rent forståelsesmæssigt kan man tænke det som:
- En error sker der crasher processen, en Error Block udenfor Main sætter en %ErrorLocal% med en mulig forklaring på fejlen.
- Error Block i Main trigger efterfølgende, som kører Global Error Handler subflowet, som henter PADs egen sidste error, og sender hele fejlrapporten til udvikleren
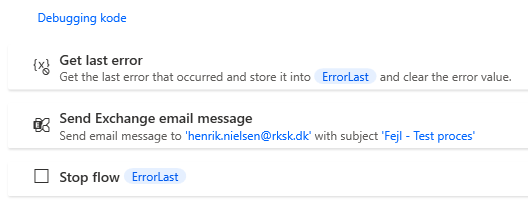
- Som note laves debugging i HTML, da det er nemmere at sætte ind som liste. Body af mailen står som – “PAD Error – %ErrorLast%<br><br>Local Error – %ErrorLocal%<br><br>Liste af fejl ved kørsel:<br>%ErrorList%“
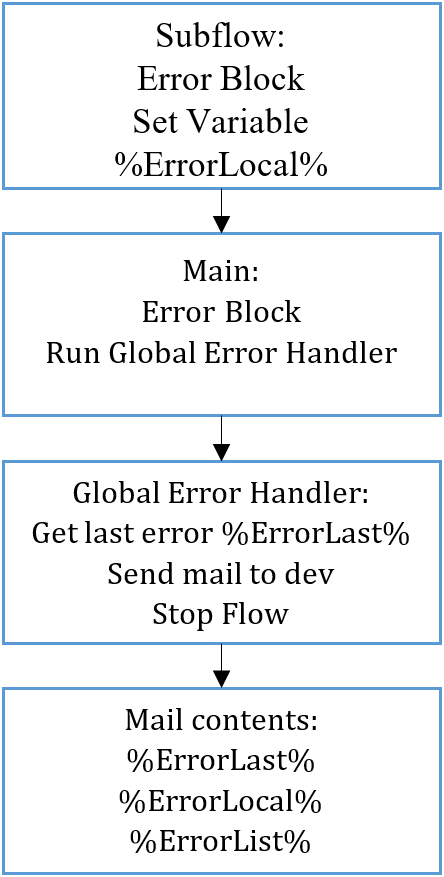
De tre variabler jeg bruger til debugging er beskrevet:
ErrorLast den fejl som PAD selv meddeler, når den crasher. Logges i Global Error Handler hvis robotten crasher helt.
ErrorList indeholder små fejl, hvor robotten kan køre videre efterfølgende. En fejl kan være som forneden, hvor vi tjekker at vi har fået en variabel, der er nødvendig for resten af kørslen. Er dette ikke tilfældet, logger vi fejlen til listen, og tager næste kørsel i loopet i stedet. Dette forhindrer robotten i at forsætte, og crashe senere i processen. Listen kan efterfølgende bruges, til at finde ud af om noget kode skal justeres, eller om det reelt er en fejl der skal tages ud til manuel behandling fremover. Det kan nogle gange også vise noget, som ikke var forventet, og der skal tages stilling til.
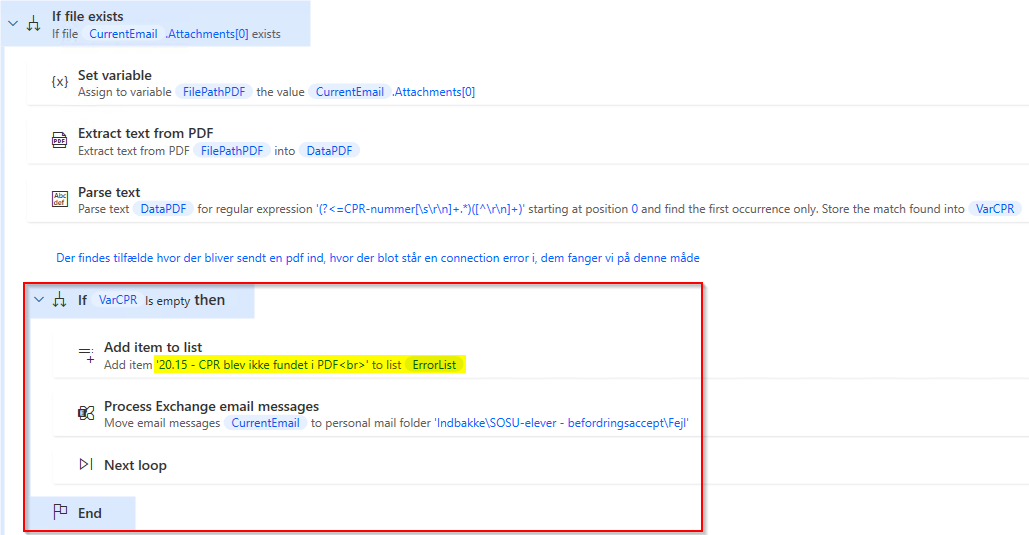
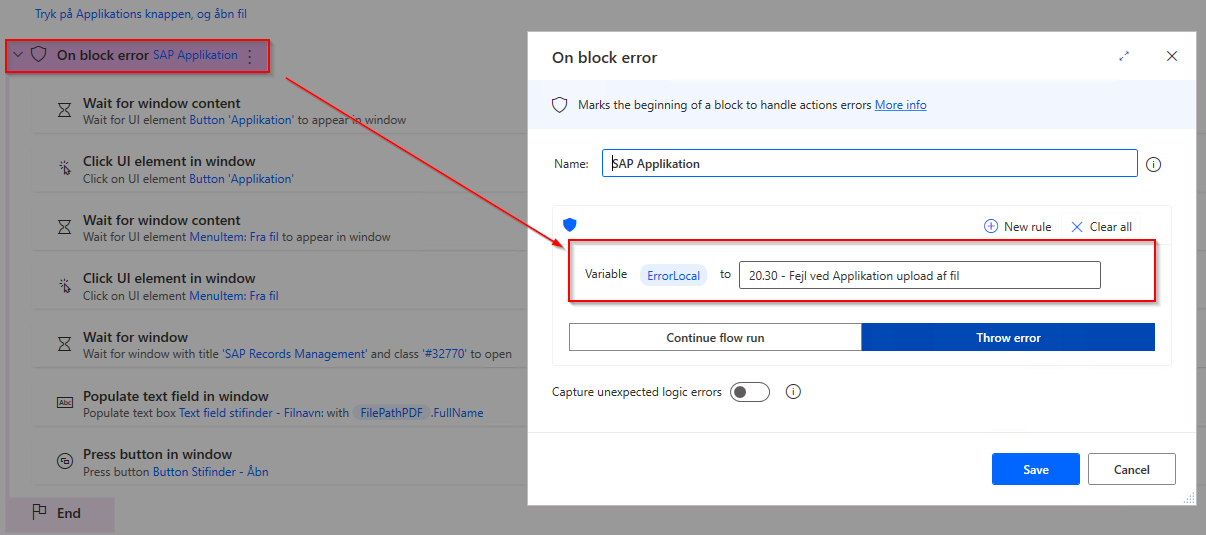
ErrorLocal en forventet fejl der kan ske, hvor jeg har skrevet noget mere sigende til hvad det er. Typisk sætter jeg disse som en On block error omkring kode der laver en lille del af en funktion. I eksemplet her er der ovenfor en blok til at håndtere, hvis den ikke kan komme ind på det rigtige billede, og under også en blok til hvis den ikke kan udfylde resten af formularen. På den måde får jeg både PADs fejl om hvilken action fejlede, men også hvad robotten forsøgte da det skete. Logges kun hvis robotten crasher helt, og kan sættes på individuelle actions også.
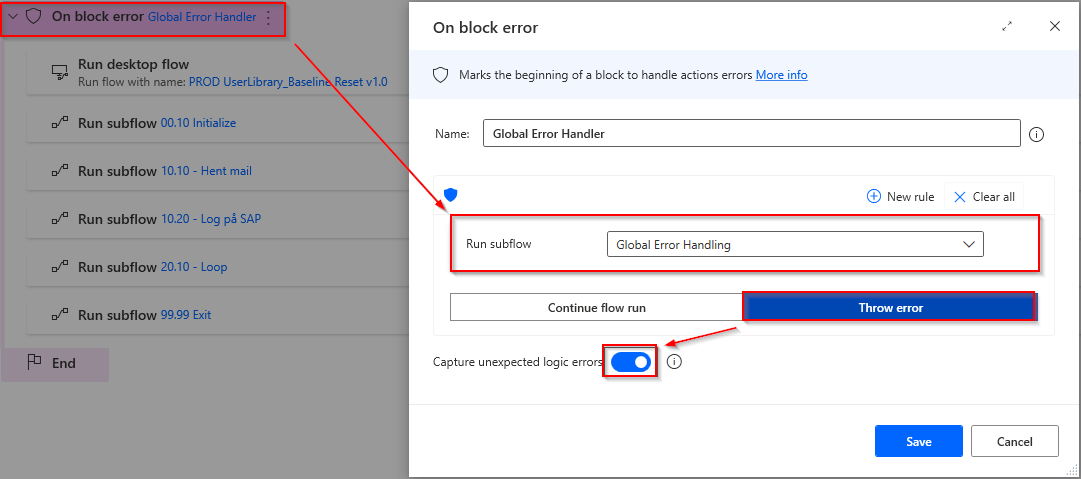
På Main sidder blokken der styrer Global Error Handler som kun bliver kaldet, såfremt at en fejl helt crasher processen. Den trigger ligegyldigt hvilket subflow laver fejlen. Selvom et subflow ikke står i Main, så trigger den forsat på kritiske fejl, såfremt et subflow er en del af de nedenstående subflows (denne inheritance forsætter uendeligt i niveauer af subflows). Eksempel 20.10 – Loop kører subflows som ikke køres i Main, hvis disse laver fejl, så trigger blokken i Main forsat, fordi de hører under 20.10 – Loop. Hvis man har brug for at køre teste processen i PAD uden denne debug, kan man slå den fra ved at deaktivere blokken.
Selve Global Error Handler ser således ud. Her sendes alt Error håndtering med i mailen, hvilket gøres via HTML-kode i body af mailen – “PAD Error – %ErrorLast%<br><br>Local Error – %ErrorLocal%<br><br>Liste af fejl ved kørsel:<br>%ErrorList%”
Selv ved en succesfuld kørsel, sender robotten ErrorList ud til udviklerne, hvis den ikke er tom. Dette for at kunne gennemgå om noget kode skal ændres eller om sådanne fejl reelt skal tages ud til manuel behandling af et menneske fremover i stedet. I 99.99 – Exit gøres dette i min egen kode.
En retur mail kan eksempelvis se således ud ved et crash. Ud fra dette kan det konkluderes at robotten var i gang med at klikke ind i en personalemappe, hvor den så ikke kunne udfylde et tekstfelt på vejen. Yderligere kan vi se, at den har haft to mindre fej den har sprunget over. Enten er der manglet et medarbejdernummer eller en dato, som skulle bruges for at kunne lave kørslen.
“PAD Error – Underflow: 20.30 – SAP gem fil i personalemappe, handling: 4, handlingsnavn: Udfyld tekstfelt i vindue Fejlmeddelelse: Kunne ikke skrive i tekstfeltet (tekstfeltet blev ikke fundet) Flere oplysninger: {}
Local Error – 20.30 – Kunne ikke navigere i personalemappen
Liste af fejl ved kørsel:
20.20 – Fandt ikke medarbejdernr tilhørende CPR “111111-5555” eller Dato “” ved SQL udtræk
20.20 – Fandt ikke medarbejdernr tilhørende CPR “555555-1111” eller Dato “20-03-2024” ved SQL udtræk“
5. Skabelon til kode #
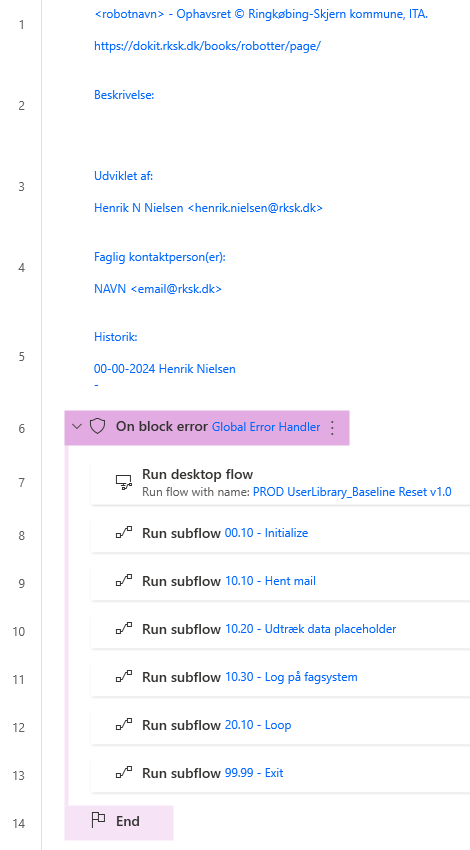
I mange tilfælde er det nemmest at lave en skabelon, som kan kopieres når der skal laves nye processer. Denne kan indeholde funktioner, variabler, debugging m.m., som altid eller næsten altid bruges på tværs af processer. Typisk har jeg de nedenstående med, foruden en tekst skabelon til dokumentation i starten af Main. Dette kan også hjælpe med at gøre tingene mere ensformigt, på tværs af udviklere eller egne processer.
| Main | Kører kun funktioner, så lidt logik som muligt, og dokumentation øverst |
| Global Error Handler | Standard debugging jeg bruger |
| 00.10 – Initialize | Laver en temp save folder, en Count variabel, liste til fejl, og henter credential ud til at sende debugging informationen, samt andet der bare sættes en gang |
| 99.99 – Exit | Logning af kørsel i SQL-tabel, udsendelse af debugging hvis der var fejl i ErrorList, og sletning af temp mappen |
| 10.10 – Hent mail | Mange af mine processer starter med at hente en mail, som er datagrundlaget for resten af udførslen. Generelt kan det også være et “Hent data” subflow |
| 10.20 – Udtræk data placeholder | Placeholder hvis der er behov for at trække noget data ud før loopet går i gang |
| 10.30 – Log på fagsystem | En placeholder hvis der er behov for at logge på noget, og sætte til en standardvisning før et loop skal køres |
| 20.10 – Loop | Kører en foreach på datagrundlaget og kalder dens subflows i en bestemt rækkefølge |
| 20.20 – Udtræk data placeholder | En placeholder til udtræk af data der skal bruges i loopet. Denne sætter alle eventuelle variabler der skal bruges i resten af loopet. |
| 20.21 – Udtræk data placeholder | Blank placeholder, hvis man skal trække ekstra meget data ud og har brug for et subflow til 20.20 |
Main ser således ud, hvor noget af dokumentation kan udfyldes eller linkes til et internt system.